
정치적 필터 버블은 출처에 따른
정보 신뢰에 영향을 주는가?
– 디지털 콘텐츠 수용에 대한 분석을 바탕으로 –
강태영
(서강대학교 4학년)
국문 초록
“정치적 필터 버블(filter bubble)의 완화는 과연 디지털 콘텐츠 분별력을 향상시킬 수 있을까”라는 사회심리학적 질문은 최근 논의되고 있는 가짜 뉴스 리터러시 문제와 결코 무관하지 않다. 이에 본 논문은 “필터 버블이 상시 존재하는 온라인 공간에서 과연 특정한 콘텐츠의 인기는 출처에 따른 디지털 콘텐츠의 표현 형식과 어떠한 관계를 맺는가”와 “만약 출처가 불분명한 콘텐츠의 인기가 불가피한 현상이라면, 과연 필터 버블의 완화가 이러한 문제를 실제로 해소할 수 있을지”의 문제를 다루었다.
연구자는 현실의 대규모 온라인 데이터를 직접 다루는 동시에 인과성에 강점을 지닌 실험 방법론을 활용하고자 하였다. 이를 위해 ①극우주의 커뮤니티 사이트인 일간베스트 저장소 정치베스트 게시판의 15,400개 게시물들을 크롤링하고, 추가적으로 ②서강대학교 인문사회계 재학생 100명을 대상으로 실험 설문을 실시하였다. 그 결과, 일베저장소 정치 게시판 내에서는 외부 콘텐츠를 공유하거나 출처를 표기하지 않은 독자 콘텐츠일수록 추천 수가 평균 약 7-8개 더 높아짐을 확인할 수 있었고, 실험 설문 연구를 통해서는 필터 버블이 완화된 집단에서 뉴스 형태 콘텐츠의 신뢰도가 평균 8%pt 가량 더 높다는 점 역시 알 수 있었다.
본 연구는 다음의 의의를 갖는다. 첫 번째, 현장(field)과 실험실(lab)의 데이터를 유기적으로 다루었으며, 데이터 전처리 및 분석 과정에서 최신의 방법론들을 적극적으로 사용하였다. 특히 대규모 웹 데이터를 직접 분석하고, 또 인과성 규명에 유리한 실험 디자인을 활용했다는 점에서 의미가 있다. 두 번째, 출처에 따른 미디어 수용이라는 문제와 정치적 필터 버블의 관계를 분석함으로서 ‘뉴스’의 형식을 띄고 있지 않은 한국형 가짜 뉴스 수용의 문제에 대해 간접적인 해답을 제시해준다.
- 연구의 배경
“네이티브 애드”라는 이름으로 광고와 실제 기사의 경계가 모호해지고, 또 진짜 뉴스와 가짜 뉴스, 오보, 루머가 혼동되는 시대. (권만우 외, 2015) 우리의 미디어는 위기에 처했다고 할 수 있다. 다만 가짜 뉴스와 진짜 뉴스, 그리고 그 인접 개념을 구분하는 것은 현실적으로 어려운 것이 사실이다. 이와 관련해 오세욱과 정세훈, 박아란의 연구 (오세욱 외, 2017)는 가짜 뉴스를 정확히 어떻게 정의해야 하는지, 그리고 그 과정에서 어떠한 개념적 모순들이 존재하는지에 대해 면밀히 분석하고 있다. 우선 가짜 뉴스는 크게 ①유머형, ②수익형, ③기만형, ④봇 생성형의 네 가지로 나눠지며 이는 기존의 미디어 콘텐츠에서 나타나는 ①풍자(satire), ②거짓말(hoax), ③정치적 선동(propaganda), ④루머(rumor), ⑤오보(false report)와도 밀접한 관계를 맺고 있다. 해당 개념들을 작성 내용, 정치·경제적 목적, 독자 기만 여부, 형식의 다섯 가지 기준을 중심으로 정리하자면, 아래의 [표 1]과 같이 정리할 수 있다.
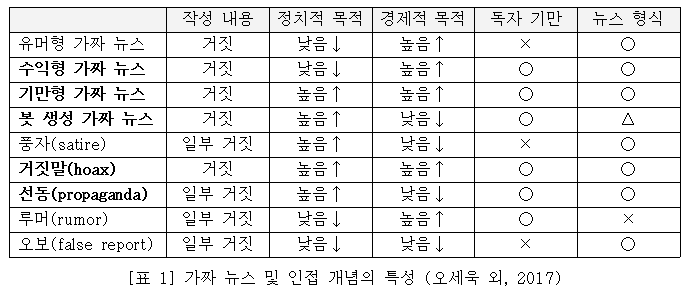
이를 바탕으로 저자는 특정 미디어 콘텐츠가 수익형/기만형/봇 생성형/거짓말/선동이라는 다섯 개 세부 유형에 속할 때에만 이를 가짜 뉴스로 분류할 수 있다고 주장하며, 구체적으로는 다음과 같이 정의한다.
“가짜 뉴스란 콘텐츠 생산이 급격히 증가한 환경에서, 원본과 작성 주체의 불명확성이라는 특성을 감안해, 그 강도에 상관없이 정치적·경제적 목적으로 거짓 내용을 작성하고, 독자를 기만할 목적으로 뉴스 형식을 차용한 거짓 정보로서 이용자가 믿을 수 있는 뉴스 형식을 갖춰 한눈에 전체 내용을 파악할 수 없는 소셜 미디어, 모바일 메신저 등 유통 플랫폼을 통해 콘텐츠 확산을 의도한 뉴스 형식의 정보이다.”
물론 개념적으로는 이러한 유형화가 가능하나, 오보와 정치적 지향이 강하게 개입된 뉴스, 악의적 편집을 통해 과장되어 현실을 묘사한 뉴스 등 인접 개념들로부터 ‘순수한 가짜 뉴스’를 현실의 사례에서 독립적으로 분류해내기는 어려운 것이 사실이다. 가령 지난 19대 대선에서의 중앙선관위 산하 가짜 뉴스 신고 센터의 경우, 실제 가짜 뉴스를 제보한다기보다는 자신의 기존 정치 지향에 배치되는 기사들을 제보하는 경향이 많았다는 사실은 이러한 특성을 여실히 드러낸다. (오세욱 외, 2017) 또한 가짜 뉴스를 웹 사이트 상에서 조직적으로 생산하고 배포하는 해외의 사례와 달리, 국내의 경우 정식 웹 사이트 형태의 가짜 뉴스 생산지가 명확히 발견된 적이 없으며, 대다수는 모바일 메신저로 확산되고 있다. 물론 가짜 뉴스의 생산 동학은 끊임없이 변화하기에 해당 양상은 일정 부분 가변적이다. 확증편향에 관한 정치심리(political psychology)적 연구들은 이러한 개념적 모호함을 더욱 확대한다. 사람들은 자신의 기존 신념과 일치하지 않는 뉴스를 가짜뉴스라고 판단하는 정도가 더 높고, 이를 외부에 전파하려 하는 의도 역시 낮은 양상을 보이기 때문이다. (염정윤 & 정세훈, 2018)
한편, 가짜 뉴스 콘텐츠와 관련해 좀 더 기술적인 분석을 시도한 연구들 역시 진행되어 왔다. 두 차례의 온라인 패널 조사를 실시한 결과, 카카오톡이나 라인 등의 모바일 메신저를 통해 선거 정보를 접할수록 가짜 뉴스 효과가 증가하는 것으로 나타났다. (노성종 외, 2017) 반면 모바일 메신저 상의 줄글보다 기사 형식의 데스크탑 화면일수록 더 높은 신뢰도를 체감한다는 상반된 연구 결과가 제시되기도 한다. (오세욱 & 박아란, 2017) 서울대 언론정보연구소의 팩트체크 서비스의 한 줄 요약 정보를 활용해 참·거짓 여부를 분류하려는 시도도 존재하나 (윤태욱 & 안현철, 2018), 그 방법론적 엄밀성의 부재로 인해 out-sample test accuracy는 약 55%에 지나지 않으며, 현실적으로 국내에서 가짜 뉴스의 대표성 있는 데이터 확보가 엄밀하지 않은 상황에서 계산적인(computational) 분석은 어려운 것이 사실이다.
정리하자면, 가짜뉴스 자체의 개념적 모호함, 조직적으로 가짜 뉴스를 유포하는 사이트의 부재 및 이에 기인한 온라인 데이터 확보의 어려움 등으로 인해, 기존의 연구들은 팩트 체크 뉴스의 배치 방식에 따른 상이한 심리적 효과 분석이나 미디어 리터러시 교육의 정보 판별 역량 증진 여부 확인 등, 간접적인 방식으로 가짜 뉴스와 관련된 경험 연구들을 진행해왔다. 물론 본 연구 역시 이와 같은 한계로부터 완전히 자유롭지는 못하나, 디지털 콘텐츠 수용이라는 문제를 보다 직접적으로 다루고자 한다.
- 연구의 목표 및 연구 설계
본 연구가 던지는 질문은 다음과 같다. “정치적 필터 버블(filter bubble)의 완화는 과연 디지털 콘텐츠 분별력을 향상시킬 수 있을까?” 필터 버블이란 개별 행위자들에게 각자의 선호에 특화된, 편향된 성향의 정보만이 제공되는 현상을 지칭하며, 소셜 미디어의 맞춤형 알고리즘의 발전과 함께 정치심리학의 주요한 문제로 부상하고 있다. 그러나 정치적 확증 편향은 온라인 공간 이전에 인간 행위자의 보편적 특성이기며, 비슷한 사회적·문화적 자본을 공유할수록 그러한 성향이 강한 것으로 알려져 있다. 즉, 필터 버블 및 이로부터 파생된 일련의 문제들은 온라인과 오프라인을 관통하는 이론적 주제이다. 따라서, 본 논문은 “필터 버블이 상시 존재하는 온라인 공간에서 특정한 콘텐츠의 인기는 출처에 따른 디지털 콘텐츠의 표현 형식과 어떠한 관계를 맺는지”와 “만약 출처가 불분명한 콘텐츠의 인기가 불가피한 현상이라면, 과연 필터 버블의 완화가 이러한 문제를 해소할 수 있을지”의 두 가지 문제에 집중했다. 이를 알아보고자 수행한 연구는 다음의 두 가지이다.
첫 번째, 정치적 성향이 명확하고 필터 버블 효과가 강력한 온라인 공간인 일간베스트저장소(이하 ‘일베’)에 대한 계량적 분석을 실시했다. 극우 커뮤니티 사이트로 알려진 일베(http://ilbe.com)는 청장년층이 합성 사진과 정치 유머 콘텐츠를 게재하는 ‘짤방 게시판’과 중노년층의 정치 토론 공간인 ‘정치 게시판’으로 양분되어 있으며, 특히 후자의 게시판에서는 진실 여부를 판별할 수 없는 획일적 정보들, 가짜 뉴스들, 편향적 기사들이 자주 게재되고 있다. 이에 연구자는 ‘정치베스트 게시판’에 2018년 3월 3일부터 10월 3일까지 총 7개월에 걸쳐 업로드 된 1만 5천여개 게시물들을 수집하였으며, 각 게시물의 인기도 1) 에 ‘외부 콘텐츠 및 그 출처 삽입 여부’가 어떠한 영향을 미치는지 알아보고자 했다.
두 번째, 인문사회계열을 중심으로 한 서강대학교 재학생(인문계 11%, 사회계 80%, 상경계 5%, 이공계 4%) 100명을 대상으로 두 번의 설문조사를 기반으로 인과성 판단을 위한 실험 연구를 실시했다. 1차 설문에는 성별, 입학년도, 전공 분야 등의 인구학적 변수와 6가지 정치성향을 묻는 질문을 포함시켰다.
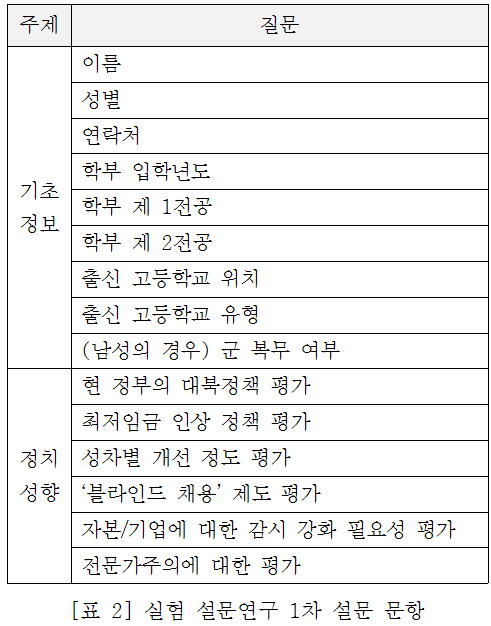
그 후, 답변 내용들을 바탕으로 난수 할당을 통해 이들을 다시 두 개 그룹을 분할하였고, 2차 설문 시에는 한 그룹에게만 1차 설문에서 다뤘던 6개 정치성향에 대한 서강대생 설문 참여자들의 응답 분포와 국민 여론, 관련 기사 등을 소개하는 파트를 처치 효과(treatment effect)로서 부여했다. 이는 자신의 의견 및 자신의 소속 집단의 편향성을 드러내어 필터 버블 효과를 완화시키기 위한 방안으로, 구체적인 제시 방식은 아래와 같다.
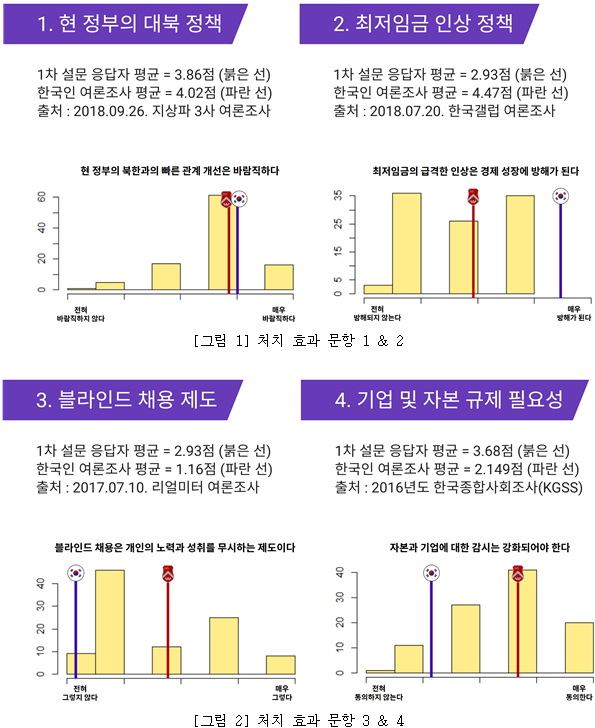
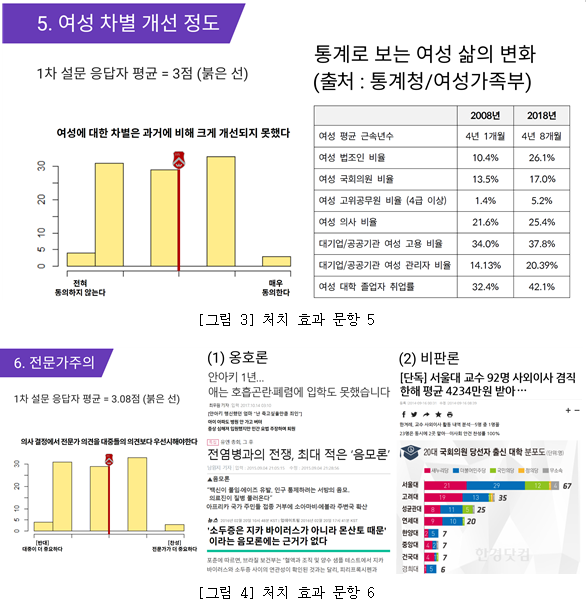
처치가 끝난 후에는, 처치 그룹(treatment group)과 통제 그룹(control group) 양쪽 모두 연구자가 직접 작성한 가상의 디지털 콘텐츠에 대한 신뢰도를 응답하게 하였다. 문항들의 내용은 다음과 같다.
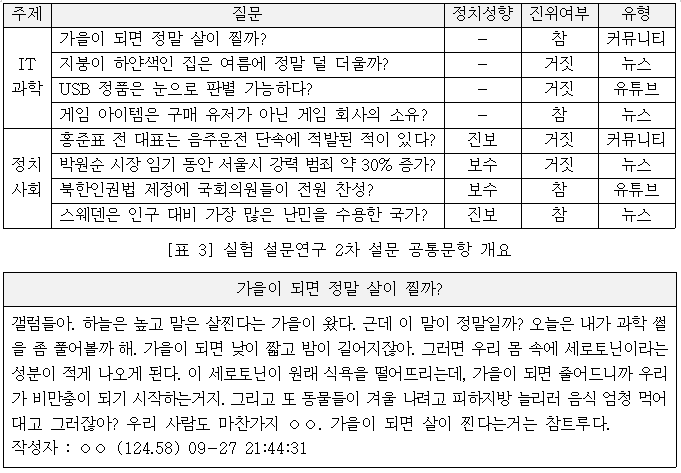




- 연구 방법론
본 연구는 웹 데이터인 일간베스트 저장소 정치 베스트 게시물들과 서강대생 대상의 실험 설문 데이터를 분석하는 것을 목표로 한다. 단 웹 데이터의 경우, 게시물의 수가 약 1만 5천 개 정도이며 이와 같은 큰 샘플 크기는 p-value를 과소 측정하는 문제를 유발할 수 있다. 이러한 문제를 해소하고자 본 논문이 제시하는 대안은 샘플 크기 의존도를 낮추는 동시에 유의미한 변수의 선택이 가능한 조정(adaptive) LASSO 정규화(regularization) 기법의 활용이다. 최소자승추정법(OLS, Ordinary Least Square)이 잔차제곱합(RSS)을 최소화하는 방식으로 작동한다면, LASSO 회귀 분석은 이에 L1 페널티를 추가시켜서 손실 함수를 재정의한다. 수학적으로 표현하면 다음과 같다. (Tibshirani, 1996)
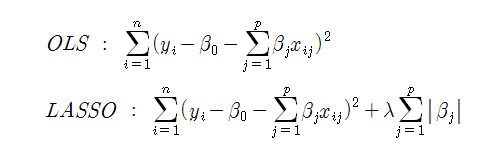
이 때 L1 penalty가 작아지기 위해서는 모델에 사용된 변수의 계수들을 0에 가깝도록 만들어야 하며 이 수축 (shrinkage) 과정은 다음의 제한 영역(constraint area, 아래 식에서는 t로 표현됨)에 관한 식으로 표현된다.
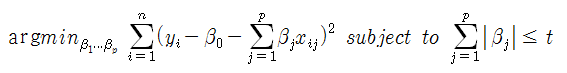
다만 LASSO의 변수 선택 방식이 안정적(robust)이지 않은 경우도 종종 존재하며, 이에 조정 가중 벡터(adaptive weights vector)를 포함하는 조정 LASSO(adaptive LASSO)가 그 대안으로 제시되었다. (Zou, 2006) 가중 조정 벡터인 를 기존 LASSO에 추가한 식은 다음과 같다.
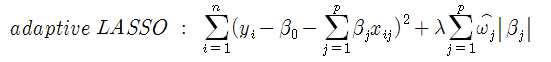
가중 조정 벡터란 일종의 추가적 페널티로, 최초 회귀 계수 추정치(initial estimate of coefficient)인 에 양의 상수 γ을 제곱하여 역수를 취한 값이다. 수식으로는 아래와 같이 표현할 수 있다.
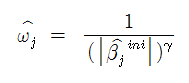
관례적으로 최초 회귀 계수 추정치 로는 능형회귀(ridge regression)를 통해 구한 값을 활용하며 연구자 역시 이와 같은 방법을 사용했다.
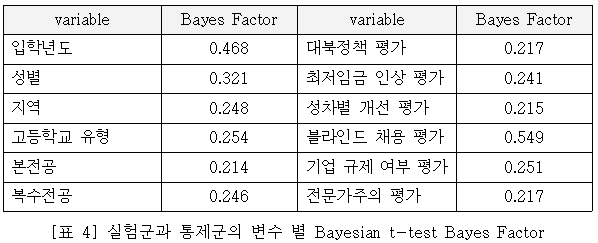
두 번째로, 1차 설문 데이터에 기반해 처치군과 통제군을 임의 할당하는 과정에는 t-SNE(t-distrib-uted stochastic neighbor embedding) 차원 축소 알고리즘과 HDBSCAN(Hierarchical Density Based Spatial Clustering of Applications with Noise) 군집화 알고리즘을 활용하였다. 1차 설문에 사용된 모든 문항들을 이원화(binary encoding) 할 경우, 이는 총 32개 변수들로 정리된다. 문제는 32차원의 데이터 상에서 거리를 기반으로 유사한 응답자들을 짝 짓는 과정에서 발생한다. 바로 차원의 저주(curse of dimensionality)로 인해, 데이터 포인트 간의 거리가 상당 부분 왜곡되어 있기 때문이다. 이에 32차원을 그보다 훨씬 작은 네 개 차원으로 축소한 후, 군집화 알고리즘을 활용해 둘 씩 짝지은 26개 군집을 확보했다. 이후 명확한 군집으로 분류되지 못한 10개 응답자들을 포함하여 이들을 실험/통제군 양쪽에 무작위 배정하였다. 이후 improper prior을 활용한 Bayesian t-test를 실행한 결과, 모든 Bayes Factor가 1 이하의 값을 보여주었으며, 이를 통해 무작위 할당이 매끄럽게 잘 이루어졌음을 사후적으로 확인해볼 수 있었다.
- 경험적 분석 결과
1) 일간베스트 저장소 – ‘정치 일간베스트’ 게시물 분석
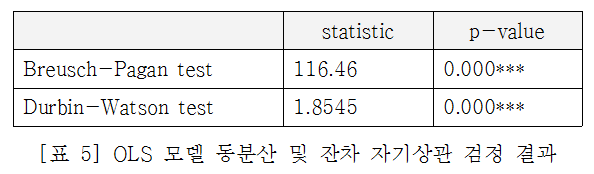
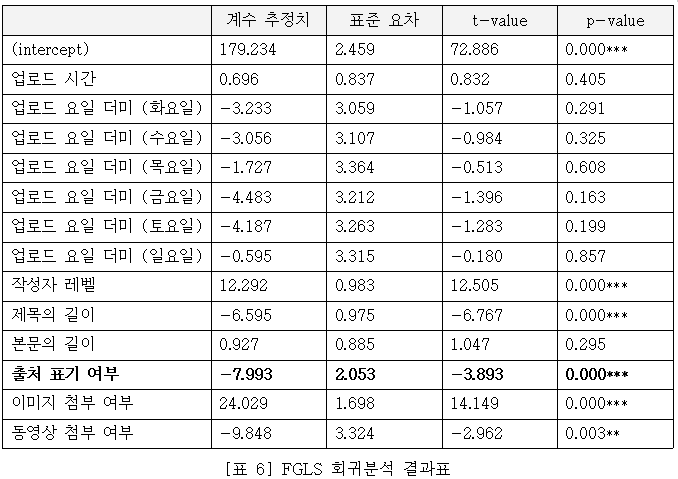
2018년 3월 3일부터 10월 3일까지의 7개월 간 작성된 게시물은 총 15,400개였으며 이 중 글 작성 후 계정을 삭제해 원 작성자의 신원이 모호해진 37개 글과 1만 번 이상의 추천을 받은 이상치 1개 글을 제외시키고 총 15,362개 게시물을 최종 분석에 활용하였다. (결측치 손실률 0.25%) 독립 변수는 ‘외부 콘텐츠 및 그 출처 삽입 여부’, 종속 변수는 게시물의 인기도(추천수-비추천수)이며 통제 변수로는 게시물의 업로드 요일, 시간대, 작성자의 레벨, 제목의 길이, 본문의 길이의 6개 지표를 활용했다. 최소자승추정(OLS) 회귀분석 모델의 동분산(homoskedasticity) 및 잔차 자기상관(auto-cor-relation) 여부에 대한 통계적 검정을 진행한 결과, 영가설이 모두 기각됨을 알 수 있었고, 이에 HC4 FGLS(Feasible Generalized Least Square)를 대안적으로 실시하였다.
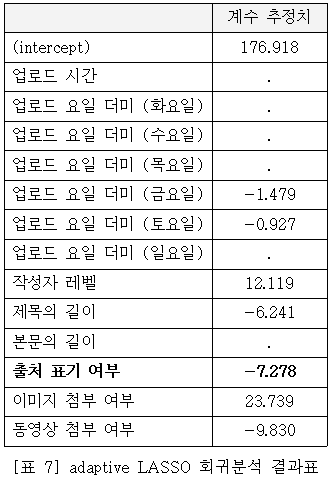
FGLS 회귀분석 및 앞서 소개한 adaptive LASSO 회귀분석의 결과표는 다음 페이지에서 확인할 수 있다. 독립변수는 모두 Z 표준화된 회귀계수이며, 따라서 변수들 간의 계수 크기를 직접적으로 비교 가능하다. 이 때 LASSO 회귀에서 유의미하지 않은 변수의 계수는 아예 값이 0으로 탈락되며 본 [표 6]에서 이는 ‘.’으로 표시하였다. 분석 결과, 게시물의 추천 수는 이미지를 사용할수록 약 24개, 동영상을 사용하지 않았을수록 약 10개 증가하였다. 또한 출처를 표기하여 외부 콘텐츠를 공유한 글일수록 오히려 추천 수가 약 7-8개 정도 감소하는 것으로 나타났다. 이는 가독성이 높고, 특별한 출처 없이 주관적인 의견을 그대로 실은 게시물들일수록 더 높은 인지도를 얻는다는 점을 시사한다.
2) 설문 실험 연구
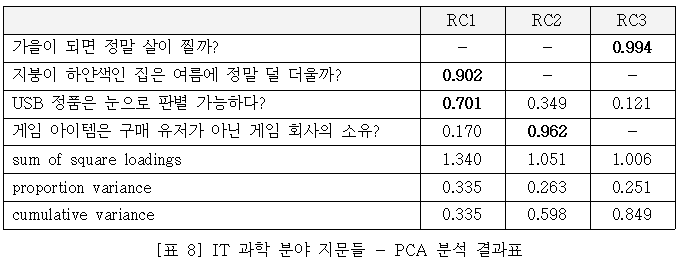
IT 과학 분야 네 개 지문과 정치 사회 분야 네 개 지문들에 대해 각각 주성분분석(PCA, Principal Component Analysis)을 실시한 결과는 아래와 같다. 전자의 경우 콘텐츠의 출처 유형과 진위 여부 모두 신뢰도에 영향을 미치지 않았으나, 후자의 경우 콘텐츠 출처 유형만이 신뢰도 판단에 영향을 준 것으로 나타났다. 또한 응답자들이 ‘웹 커뮤니티 게시물’과 ‘동영상 대본’을 각기 다른 유형으로 인지하고 있다는 점 역시 확인할 수 있었다.
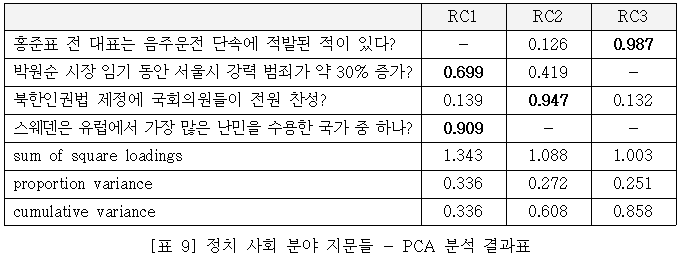
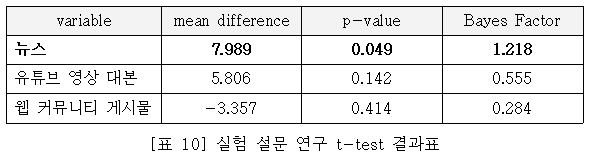
[표 8]의 세 개 주성분(RC1=뉴스, RC2=유튜브, RC3=웹 커뮤니티) 각각에 대해 t-test를 실시한 결과, 필터 버블 완화 처치를 실시한 집단은 뉴스 형태의 콘텐츠에 대해 약 8%pt 높은 신뢰도를 보이는 것으로 나타났다. 또한 적은 표본 수에서 통계 분석의 강건성(robustness)확보를 위해 빈도주의 t-test에서의 p-value와 베이지언 t-test에서의 Bayes Factor 두 가지를 함께 표시하였다.
- 결론 – 한계 및 의의
“정치적 필터 버블(filter bubble)의 완화는 과연 디지털 콘텐츠 분별력을 향상시킬 수 있을까”라는 사회심리학적 질문은 최근 논의되고 있는 가짜 뉴스 리터러시 문제와 결코 무관하지 않다. 이에 본 논문은 “필터 버블이 상시 존재하는 온라인 공간에서 과연 특정한 콘텐츠의 인기는 출처에 따른 디지털 콘텐츠의 표현 형식과 어떠한 관계를 맺는가”와 “만약 출처가 불분명한 콘텐츠의 인기가 불가피한 현상이라면, 과연 필터 버블의 완화가 이러한 문제를 실제로 해소할 수 있을지”의 문제를 다루었다.
연구자는 현실의 대규모 온라인 데이터를 직접 다루는 동시에 인과성에 강점을 지닌 실험 방법론을 활용하고자 하였다. 이를 위해 ①극우주의 커뮤니티 사이트인 일간베스트 저장소 정치베스트 게시판의 15,400개 게시물들을 크롤링하고, 추가적으로 ②서강대학교 인문사회계 재학생 100명을 대상으로 실험 설문을 실시하였다. 그 결과, 일베저장소 정치 게시판 내에서는 외부 콘텐츠를 공유하거나 출처를 표기하지 않은 독자 콘텐츠일수록 추천 수가 평균 약 7-8개 더 높아짐을 확인할 수 있었고, 실험 설문 연구를 통해서는 필터 버블이 완화된 집단에서 뉴스 형태 콘텐츠의 신뢰도가 평균 8%pt 가량 더 높다는 점 역시 알 수 있었다.
본 연구의 의의는 크게 두 가지로 요약될 수 있다. 첫 번째, 현장(field)과 실험실(lab)의 데이터를 유기적으로 다루었으며, 데이터 전처리 및 분석 과정에서 최신의 방법론들을 적극적으로 사용하였다. 특히 대규모 웹 데이터를 직접 분석하고, 또 인과성 규명에 유리한 실험 디자인을 활용했다는 점에서 의미가 있다. 두 번째, 출처에 따른 미디어 수용이라는 문제와 정치적 필터 버블의 관계를 분석함으로서 ‘뉴스’의 형식을 띄고 있지 않은 한국형 가짜 뉴스 수용의 문제에 대해 간접적인 해답을 제시해주고 있다. 온오프라인 공간에서 계속되고 있는 폐쇄적 정치 네트워크를 해소한다면, 이는 검증된 뉴스 콘텐츠에 대한 신뢰도 향상으로 연결될 수 있을 것이기 때문이다.
물론 이론적·경험적 보완 역시 필요하다. 첫 번째, 본 논문에서는 시간적 제약으로 인해 일베 저장소 내 게시물들의 구체적인 내용을 분석하지는 못했으나, 이후 토픽 모델링 및 word2vec과 GloVe를 활용한 단어 임베딩 등을 적용해 분석 모델을 보다 정교화 해야 할 필요가 있다. 두 번째, 설문 연구의 경우, 일회성 설문만으로는 그 효과를 확신할 수 없기에 부가적인 실험을 거쳐 본 분석 결과를 보다 체계적으로 이론화해야 할 것이다.
- 참고문헌
권만우, 전용우, and 임하진. “가짜뉴스 (Fake News) 현황분석을 통해 본 디지털매체 시대의 쟁점과 뉴스콘텐츠 제작 가이드라인.” 멀티미디어학회논문지 18.11 (2015): 1419-1426.
오세욱, 정세훈, and 박아란. “가짜뉴스 현황과 문제점.” 연구서 2017-06. 한국언론진흥재단 (2017)
노성종, 최지향, and 민영. “‘가짜뉴스효과’의 조건.” 사이버커뮤니케이션학보 34.4 (2017): 99-149.
염정윤, and 정세훈. “가짜뉴스에 대한 인식과 팩트체크 효과 연구.” 한국언론학보 62.2 (2018): 41-80.
오세욱, and 박아란. “일반 국민들의 가짜 뉴스에 대한 인식” 미디어이슈웹진 3권 3호(2017): 1-13.
윤태욱, and 안현철. “텍스트 마이닝과 기계 학습을 이용한 국내 가짜뉴스 예측.” Journal of Information Technology Applications & Management 25.1 (2018): 19-32.
각주
1) 추천수 – 비추천수로 계산하였다


